Les trois parties d'un script serveur
Si l'on décortique quelques pages actives, on se rend vite compte
qu'il y a toujours 3 parties importantes dans les scripts :
- Affichage de l'information : texte, liste, formulaire. C'est
sur cette page HTML que l'utilisateur fera des choix : des boutons, des
liens sont à sa disposition.
- Aiguillage. En fonction d'où provient l'utilisateur
et de l'action qu'il a choisie, on définit ce que l'on va faire.
- Traitements. C'est dans cette partie que l'on va mettre à
jour les informations sur le serveur, que l'on va préparer les
listes ou les informations provenant du serveur. C'est la partie réception,
terme utilisé en transactionnel.
Ces parties peuvent être dans un même source, dans plusieurs,
peu importe ! L'analyse est la même, nous reviendrons sur le découpage
plus loin. Prenons quelques conventions de vocabulaire :
- page HTML : ce qui est envoyé au navigateur, issu en ce qui
concerne notre propos de l'exécution d'un script serveur.
- fichier script : fichier texte contenant certes du HTML amis aussi
du code de notre script. Un fichier source peut très bien générer
plusieurs pages HTML gébérées en fonction du contexte.
Cela sera étudié avec le découpage.
Un exemple : gestion de fiches d'informations
Pour étayer mon propos, je vais prendre l'exemple d'un panneau
de gestion de fiches d'information stockées sur le serveur. Aucune
option n'est prise ni sur le type de stockage de ces informations, ni
sur le langage de script. Un rapide tour des besoins nous donnent ceci
:
- formulaire de recherche ;
- liste de réponses ;
- page de détail : fiche en elle-même ;
- modification ou supression de la fiche ;
- ajout d'une fiche
Cet exemple courant n'est pas très sophistiqué, mais si
on voit vite que les chemins que peuvent emprunter l'utilisateur sont
nombreux et il n'est pas du tout possible de les envisager. En effet,
sur une page de fiche, il peut cliquer sur un lien et aller voir ailleurs,
il peut modifier, supprimer la fiche ou ne rien faire etc.. Il vaut mieux
regarder cette application comme un diagramme d'états, un automate
d'états finis. Les états sont les pages HTML présentées
à l'utilisateur, les actions sont les transitions. Les diagrammes
d'états-transitions d'UML nous permettent de présenter clairement
nos besoins. Pour en savoir plus sur les diagrammes d'états-transitions,
je vous propose la lecture de cette page http://uml.free.fr/cours/i-p20.html,
qui fait partie d'un site bien fait qui permet d'appréhender UML
dans de bonnes conditions.
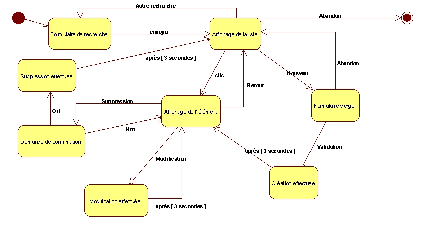
Diagramme d'états-transitions de notre exemple
On peut critiquer ce que j'ai envisagé, l'adapter, mais en l'état
ce n'est pas très loin de la réalité, et cela suffira
à ma démonstration.
(Cliquez pour voir le diagramme en plein écran)
Afin de ne pas alourdir le diagramme, les transitions issues de clics
sur des liens sortant de notre champ de gestion, équivalents donc
à un abandon ne sont pas toutes représentées.
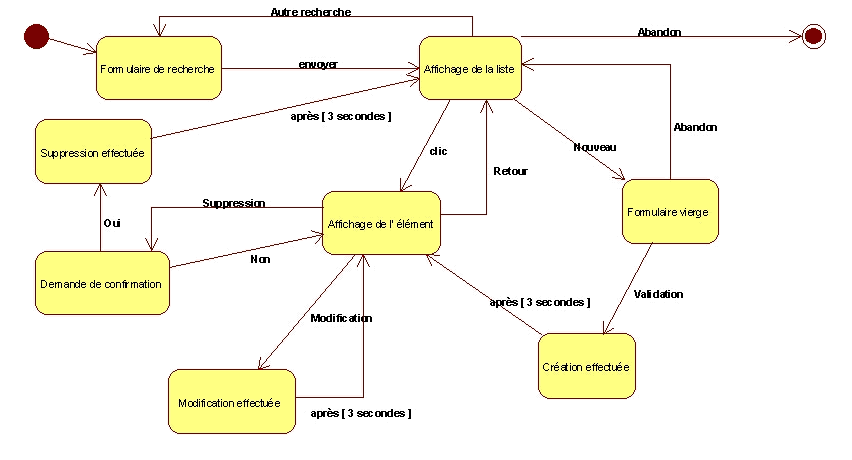
Codage du script serveur
A partir de ce diagramme, l'écriture du code est simple. Nous
découpons notre script en trois parties : traitement, aiguillage
et affichage. Chacun des états de notre diagramme se retrouve dans
ces trois parties. Un identifiant d'état conservé d'une
page HTML à l'autre est nécessaire. Il nous servira d'identifiant
de page. D'autres informations fonctionnelles doivent sûrement être
entretenues, mais je ne m'intéresse qu'à l'aspect technique
du code.
Dans chacune des parties, nous avons ou une succession de « if
»ou un « switch..case » si le langage le supporte,
portant sur la valeur de l'état en cours :
- Suivant l'état
- initial
- formulaire
- affichage liste
- etc..
On retrouve bien sûr chacun des états de notre diagramme.
Ce qui donne, pour quelques états :
- Réception : on traite les informations en fonction de l'état
passé de la pag.
- initial : rien a priori, des initialisations, etc..
- formulaire
- Si "envoyer" recherche sur le serveur des fiches correspondant
aux infos du formulaire
- affichage liste
- Si "clic" recherche des inforamtions de la fiche afin
de pré-remplir le formulaire
- demande de confirmation
- "oui" : suppression de la fiche dans l'annuaire serveur
- etc ..
- Aiguillage : on calcule l'état futur utilisé dans la
séquence affichage
- Suivant l'état
- initial
- formulaire
- Si "envoyer" nouvel état : affichage de liste
- affichage liste
- Si "clic" nouvel état : affichage de l'élément
- Si "nouveau" nouvel état : formulaire vierge
- etc ..
- Affichage
- Suivant l'état
- initial :
- On n'arrive jamais dans l'état initial à l'affichage
- du moins tel que j'ai conçu mon application, ce qui me
permet dans la partie réception de l'état initial
d'effectuer des initialisations. On pourrait très bien envisager
un état initial avec affichage d'un menu : recherche par
formulaire ou liste complète.
- formulaire :
- Affichage du formulaire avec les données de la fiche
- affichage liste :
- Utilisation des informations en provenance du serveur et affichage
- formulaire vierge
- etc..
Je n'ai pas écrit tout le pseudo-code car cela n'aurait rien
apporté à la présentation de ce cas d'école.
Découpage des sources
Combien de sources allons-nous écrire ? Pour ma part, je ne fait
qu'un fichier source pour l'équivalent d'un cas d'utilisation.
Les liens et les formulaires décrits dans le diagramme pointent
toujours vers le même fichier et c'est toujours la même URL
qui est utilisée, à la zone de «query» prêt
le cas échéant - bien que je préfére l'utilisation
des champs cachés ou des sessions.
Mais rien n'empêche de faire plusieurs fichiers. Un inconvénient
majeur que je vois à ce découpage multi-fichiers apparaît
lors d'évolution, il faudra alors modifier plusieurs fichiers pour
prendre en compte le nouvel état et ses transitions. On perd la
structuration obtenu lors de notre analyse.
Si les outils de modélisation UML ne génèrent pas
encore ce type de code, ils ont pour la plupart des extractions en ASCII
(XML par exemple) ou une interface de programmation qui nous permet de
développer des générateurs simples.
Conclusion
On peut faire la même chose sans UML, sans diagramme. Mais le
diagramme et le support de vocabulaire et d'organisation d'UML permettent
de bien clarifier les enchaînements de traitements des pages Web
et l'on a une partie de la documentation de l'application, ce qui n'est
pas négligeable.
On s'aperçoit aussi que la maintenance d'un tel script est assez
facile, l'ajout d'un état consiste « juste » en l'ajout
d'un branche supplémentaire à la structure conditionnelle.
A partir d'une analyse simple et clairement présentée, on
obtient un code propre et bien structuré.
Daniel Lucazeau
ajornet.com
Chef de projet Internet
| 
 Imprimer
Imprimer Donner votre avis
Donner votre avis